Music Monday -- October 1, 2012
01 Oct 2012"We Were Wild", by Today The Moon, Tomorrow The Sun.
It's catchy pop. The video is insipid, so we'll stick with the SoundCloud player.
Tags: musicmonday mondaymusic
"We Were Wild", by Today The Moon, Tomorrow The Sun.
It's catchy pop. The video is insipid, so we'll stick with the SoundCloud player.
Tags: musicmonday mondaymusic
On Tuesday I attempted migrating the Bacula database at work from MyISAM to InnoDB. In the process, I was also hoping to get the disk space down on the /var partition where the tables resided; I was runnig out of room. My basic plan was:
Here was the shell script I used to split the dump file, change the engine, and reload the tables:
csplit -ftable /net/conodonta-private/export/bulk/bacula/bacula.sql '/DROP TABLE/' {*}
sed -i 's/ENGINE=MyISAM/ENGINE=InnoDB/' table*
for i in table* ; do mv $i $(head -1 $i | awk '{print $NF}' | tr -d '`' | sed -e's/;/.sql/') ; done
for i in $(du *sql | sort -n | awk '{print $NF}') ; do echo $i; mysql -u bacula -ppassword bacula < $i ; done
(This actually took a while to settle on, and I should have done this part of things well in advance.)
Out of 31 tables, all but three were trivially small; the big ones are Path, Filename and File. File in turn is huge compared with the others.
I had neglected to turn off binary logging, so the partition kept filling up with binary logs...which took me more than a few runs through to figure out. Eventually, late in the day, I switched the engines back to MyISAM and reloaded. That brought disk space down to 64% (from 85%). This was okay, but it was a stressful day and one that I'd brought on myself for now preparing well.
When next I do this, I will follow this sequence:
This cool: 37 Signals released sub, a framework for easy subcommands. Think "git [whatever]", "git help [whatever]", etc. Code's up on github.
Tags: programming
For future reference: this Stack Exchange question asks how best to scan a PDF for malware. There are a number of links suggested:
I've got some reading to do.
Tags: security
So Professor Michael Geist is running for a spot on the CIRA board of directors. I want to vote for him. While I'm there I decide I should really consider the other candidates as well. And after a very small number of bios, it becomes very obvious that many -- maybe most -- are focussing on growth, on marketing, on things that would never occur to me to be part of what I thought was such an exclusively technical domain. More fool me, I guess.
Example statement from candidate Jennifer Shelton, in answer to the question: "What specific actions do you propose to overcome [CIRA's] challenges and opportunities?"
Slowing organic growth rates will require CIRA to articulate, convey, and deliver on a clear brand message that makes the value proposition clear to all stakeholders. This message should include thought and technological leadership to differentiate dot-ca from lower cost alternatives.
GAH. GAH is my reaction. I can see what is probably meant, what I could rephrase in a way that doesn't make me twitch, what would let me avoid screwing up my face at the mention of this candidate's name -- but I'm damned if I can figure out why I should bother.
Not just her. John King writes:
New competition from generic Top Level Domains (gTLDs) will arrive this year. More than ever, CIRA needs to be focused and decisive with marketing and strategic planning. CIRA needs the wisdom, the oversight and the support of a knowledgeable and committed Board of Directors to help shape the plan and to authorize appropriate action without hesitation.
And:
CIRA is a high-performing organization. There is excellent leadership from the CEO and in the functional areas. There is a culture of innovation, achievement and respect. It's easy to be enthusiastic about CIRA's very significant benefits for all Canadians and the organization's continuing recognition as an international exemplar of best practice in the domain industry.
(He goes on to compliment CIRA's "intentional [evolution] toward greater effectiveness. Intelligent organizational design FTMFW!)
The further segmentation of the top domain name space will inherently reduce some demand for .ca top level domain names. With many Canadian companies focused on export markets and the possible availability of custom specialized top level domains, the .ca top level domain space may find itself facing limited growth and it may be a challenge to project relevance to many Canadian potential registrants. It will be critical for CIRA to project value to the registrants and seek to maximize its relevance in the more complex and splintered top level domain space in the near future.
William Gibson (no, not THAT Wm. Gibson):
The issue is a marketing one. I believe what is needed is a two pronged approach. The first element would be designed to make the public much more aware of the .ca domain name designation and to make the designation much more attractive to and desirable for the users.
- Encourage true value innovation
- Continued growth, sound financial practices and investigate new revenue sources to ensure sufficient investment in our future
CIRA needs to engage its stakeholders to understand their needs and expectations and prioritize targeted solutions.
By way of welcome relief, Adrian Buss is just plain confusing:
Members of the board of directors have to be seen to be the end product that CIRA delivers. The membership is at the core of CIRA's governance model, without an engaged membership .CA just becomes an irrelevant TLD.
Jim Grey says, let's carpet the registrars with flyers:
Continuing to increase our .ca brand awareness and preference with Canadians and to strengthen our relationship with registrars. In an increasingly competitive world the .ca brand awareness becomes key to continued growth. In addition our only sales channel to market is through registrars who will be inundated with new gTLD's and increased sales incentives from existing gTLD's. CIRA will need to strengthen the relationship with registrars.
The only thing Rob Villeneuve's missing is the cape:
I understand my role as a director is to implement CIRA's mission, adopt CIRA's vision, and live CIRA's values in my personal and professional affairs, both with CIRA and in my office as CEO of a group of registrars. I will at all times reflect CIRA's brand and show my pride for .CA, which is the foremost Canadian internet identity for a domain.
Victoria Withers sez:
Continued implementation and deployment of current technology by skilled professionals will provide the environment for an agile, secure and stable registry service. Focusing on a talent management program for all areas of the business will foster and create a culture of excellence.
Third person person is third person:
For instance, Rick Sutcliffe would best represent the interests of academics (among the first ever connected to the net), small business, and non-profits. He is also a fiscal conservative.
Also, "dot polar bear for all!":
In addition, [Rick Sutcliffe] believes that CIRA can better promote its brand to Canadians, so that when they think "Internet" they think CIRA, and when they think "domain" they automatically think ".ca".
With the many new TLDs now coming on line, he is more convinced than ever that CIRA needs to expand its product line, offering registry services for any new TLD that has relevance to its mandate for Canadians.
There's the odd mention of IPv6 or DNSSEC. One candidate mentions IDN French language support. (Sorry, two.) And one, bless their heart, talks about the downside of a .CA domain having its SSL certificate revoked by a foreign SSL cert registry.
I know this rant is not constructive. I know that short-sightedness lives in my heart, that my moral failure is that I'm unable to stop twitching at the jargon and see the good ideas that (may) lurk within. I know that I'm giving Michael Geist and Kevin McArthur a free pass...doubly so for McArthur, who talks about launching "a parallel alternative root as a contingency planning exercise and as deterrent to foreign political interference within the global root zone", which is a BIG can of worms that is not (and cannot be) discussed in nearly enough depth in a 500 word essay to be used as a campaign plank.
But oh god, the...the relentless focus on growth, growth, GROWTH is enough to make me want to huddle in the corner with a bag of chips and a copy of "Das Kapital" on my laptop.
News flash: organizations evolve toward self-perpetuation. Film at 11.
Thanks to OCSNG, I just came across Munki. From their description:
Munki is a set of tools that, used together with a webserver-based repository of packages and package metadata, can be used by OS X administrators to manage software installs (and in many cases removals) on OS X client machines.
Munki can install software packaged in the Apple package format, and also supports Adobe CS3/CS4/CS5/CS6 Enterprise Deployment "packages", and drag-and-drop disk images as installer sources.
Additionally, Munki can be configured to install Apple Software Updates, either from Apple's server, or yours.
All that and it's Apache-licensed, too.
Tags: apple
"Solid Ground", by Maps and Atlases:
A couple of years ago, I rediscovered contemporary music. That's a story in itself. This is one of the songs that made me think, "Whoah...there is some really, really good stuff out there."
Tags: mondaymusic musicmonday
My wife's out tonight. I was going to use this time to due some surgery on the home network, but instead I spent my time playing Monopoloy with the kids and putting 'em to bed way past their bedtime. So now? It's nachos, beer and Netflix. I think that's fair.
Tags: geekdad
How to find out which MySQL engine you're using for a particular database or table? Run this query:
SELECT table_schema, table_name, engine FROM INFORMATION_SCHEMA.TABLES;
Thanks to Electric Toolbox for the answer.
Tags: mysql
Over the last two days, in a frenzy of activity, I got some awesome done at work: using git and Vagrant, I finally got Cfengine to install packages in Ubuntu without asking me any goram questions. There were two bits involved:
Telling Apt to use old config files. This prevents it from asking for confirmation when it comes across your already-installed-with-Cfengine config file. Cfengine doesn't do things in a particular order, and in any case I do package installation once an hour -- so I might well have an NTP config file show up before the NTP package itself.
Preseeding, which I've known about for a while but have not had a chance to get right. My summer student came up with a script to do this, and I hope to be able to release it.
Now: Fully automated package installation FTMFW.
And did you know that Emacs can check your laptop battery status? I didn't.
"The National Anthem", by Radiohead.
I showed the video to my wife recently, and as is their wont my two sons came up to watch. The 4-yr old quickly wandered off, bored that it wasn't Spider-Man or some such, but 6 stayed for the whole thing. I wonder what was going through his head; there's a lot in this that we've rarely talked about with him: religion, ritual, race relations (alliteration unintentional), and of course the flat-out jazz weirdness of the final breakdown...which I love, but I can't help but think it's an acquired taste.
Fim D'aemission.
Tags: mondaymusic musicmonday
Last year I came across the issue of reproducible science: the question of how best to ensure that published science can be reproduced by other people, whether because you want to fight fraud or simply be sure that there's something really real happening. I'm particularly interested in the segment of this debate that deals with computer-driven science, its data and its source code. Partly that's because I very much believe in Free as in Freedom, and partly it's because of where I work: a lot of the people I work with are doing computer-driven scientific research, and dealing with source code (theirs and others) is very much part of my job.
So it was interesting to read a blog post from Iddo Friedberg called "Can we make accountable research software?" Friedberg is an actual scientist and everything (and an acquaintance of my boss, which was a surprise to me). He wrote about two aspects of scientific programming that I hadn't realized before:
the prevalence -- no, requirement -- of quick, prototype code, much of it to be discarded when the hypothesis it explores doesn't pan out
the inability to get funding for maintaining code, or improving it for public use
As a result, code written by scientists (much of it, in his words, "pipeline hacks") is almost never meant to be robust, or used by others, or broadly applicable. Preparing that code for a paper is even more work than writing the paper itself. But just dumping all the code is not an option, either: "No one has the time or energy to wade through a lab's paper- and magnetic- history trail. Plus, few labs will allow it: there is always the next project in the lab's notebooks and meetings, and no one likes to be scooped." And even if you get past all that, you're still facing trouble. What if:
a reviewer can't make the code compile/run and rejects the paper?
the code really isn't fit for human consumption, and there are lots of support demands his lab can't fulfill?
someone steals an idea latent in his code and his lab gets scooped?
Friedberg's solution: add an incentive for researchers to provide tested, portable code. The Bionformatics Testing Consortium, of which he's a member, will affix gold stars to papers with code that volunteer reviewers will smoke-test, file bugs against and verify against a sample dataset. Eventually, the gold star will signify a paper that's particularly cool, everyone will want one, and we'll have all the code we need.
However, even then he's not sure that all code needs to be released. He writes in a follow-up post:
If the Methods section of the paper contain the description and equations necessary for replication of research, that should be enough in many cases, perhaps accompanied by code release post-acceptance. Exceptions do apply. One notable exception would be if the paper is mostly a methods paper, where the software -- not just the algorithm -- is key.
[snip]
Another exception would be the paper Titus Brown and Jonathan Eisen wrote about: where the software is so central and novel, that not peer-reviewing it along with he paper makes the assessment of the paper's findings impossible.
(More on Titus Brown and the paper he references ahead.)
There were a lot of replies, some of which where in the Twitter conversation that prompted the post in the first place (yes, these replies TRAVELED THROUGH TIME): things like, "If it's not good enough to make public, why is it good enough to base publications on?" and "how many of those [pipeline] hacks have bugs that change results?"
Then there was this comment from someone who goes by "foo":
I'm a vanilla computer scientist by training, and have developed a passion for bioinformatics and computational biology after I've already spent over a decade working as a software developer and -- to make things even worse -- an IT security auditor. Since security and reliability are two sides of the same coin, I've spent years learning about all the subtle ways software can fail.
[snip]
During my time working in computational biology/bioinformatics groups, I've had a chance to look at some of the code in use there, and boy, can I confirm what you said about being horrified. Poor documentation, software behaving erratically (and silently so!) unless you supply it with exactly the right input, which is of course also poorly documented, memory corruption bugs that will crash the program (sucks if the read mapper you're using crashes after three days of running, so you have to spend time to somehow identify the bug and do the alignment over, or switch to a different read mapper in the hope of being luckier with that), or a Perl/Python-based toolchain that will crash on this one piece of oddly formatted input, and on and on. Worst of all, I've seen bugs that are silent, but corrupt parts of the output data, or lead to invalid results in a non-obvious way.
I was horrified then because I kept thinking "How on earth do people get reliable and reproducible results working like this?" And now I'm not sure whether things somehow work out fine (strength in numbers?) or whether they actually don't, and nobody really notices.
The commenter goes on to explain how one lab he worked at hired a scientific programmer to take care of this. It might seem extravagant, but it lets the biologists do biology again. (I'm reminded of my first sysadmin job, when I was hired by a programmer who wanted to get back to programming instead of babysitting machines.) foo writes: "It's also noteworthy that having technical assistants in a biology lab is fairly common -- which seems to be a matter of the perception of "best practice" in a certain discipline." Touche!
Deepak Singh had two points:
Meanwhile, Greg Wilson got some great snark in:
I might agree that careful specification isn't needed for research programming, but error checking and testing definitely are. In fact, if we've learned anything from the agile movement in the last 15 years, it's that the more improvisatory your development process is, the more important careful craftsmanship is as well -- unless, of course, you don't care whether your programs are producing correct answers or not.
[snip]
[Rapid prototyping rather than careful, deliberate development] is equally true of software developed by agile teams. What saves them from [code that is difficult to distribute or maintain] is developers' willingness to refactor relentlessly, which depends in turn on management's willingness to allow time for that. Developers also have to have some idea of what good software looks like, i.e., of what they ought to be refactoring to. Given those things, I think reusability and reproducibility would be a lot more tractable.
Kevin Karplus doubted that the Bioinformatics Testing Consortium would do much:
(He also writes that the volunteers who are careful software developers are not the main problem -- which I think misses the point, since the job of reviewer is not meant to be punishment for causing a segfault.)
He worries that providing the code makes it easy to forget that proper verification of computational methods comes from an independent re-implementation of the method:
I fear that the push to have highly polished distributable code for all publications will result in a lot less scientific validation of methods by reimplementation, and more "ritual magic" invocation of code that no one understands. I've seen this already with code like DSSP, which almost all protein structure people use for identifying protein secondary structure with almost no understanding of what DSSP really does nor exactly how it defines H-bonds. It does a good enough job of identifying secondary structure, so no one thinks about the problems.
C. Titus Brown jumped in at that point. Using the example of a software paper published in Science without the code being released, he pointed out that saying "just re-implement it independently" glosses over a lot of hard work with little reward:
[...] we'd love to use their approach. But, at least at the moment, we'd have to reimplement the interesting part of it from scratch, which will take a both solid reimplementation effort as well as guesswork, to figure out parameters and resolve unclear algorithmic choices. If we do reimplement it from scratch, we'll probably find that it works really well (in which case Iverson et al. get to claim that they invented the technique and we're derivative) or we'll find that it works badly (in which case Iverson et al. can claim that we implemented it badly). It's hard to see this working out well for us, and it's hard to see it working out poorly for Iverson et al.
But he also insisted that the code matters to science. To quote at length:
All too often, biologists and bioinformaticians spend time hunting for the magic combination of parameters that gives them a good result, where "good result" is defined as "a result that matches expectations, but with unknown robustness to changes in parameters and data." (I blame the hypothesis-driven fascista for the attitude that a result matching expectations is a good thing.) I hardly need to explain why parameter search is a problem, I hope; read this fascinating @simplystats blog post for some interesting ideas on how to deal with the search for parameters that lead to a "good result". But often the result you achieve are only a small part of the content of a paper -- methods, computational and otherwise, are also important. This is in part because people need to be able to (in theory) reproduce your paper, and also because in larger part progress in biology is driven by new techniques and technology. If the methods aren't published in detail, you're short-changing the future. As noted above, this may be an excellent strategy for any given lab, but it's hardly conducive to advancing science. After all, if the methods and technology are both robust and applicable to more than your system, other people will use them -- often in ways you never thought of.
[snip]
What's the bottom line? Publish your methods, which include your source code and your parameters, and discuss your controls and evaluation in detail. Otherwise, you're doing anecdotal science.
I told you that story so I could tell you this one.
I want to point something out: Friedberg et al. are talking past each other because they're conflating a number of separate questions:
When do I need to provide code? Should I have to provide code for a paper as part of the review process, or is it enough to make it freely available after publication, or is it even needed in the first place?
If I provide it for review, how will I ensure that the reviewers (pressed for time, unknown expertise, running code on unknown platforms) will be able to even compile/satisfy dependencies for this code, let alone actually see the results I saw?
If I make the code available to the public afterward, what obligations do I have to clean it up, or to provide support? And how will I pay for it?
Let's take those in order, keeping in mind that I'm just a simple country sysadmin and not a scientist.
When do I need to provide code? At the very least, when the paper's published. Better yet, for review, possibly because it gets you a badge. There are too many examples of code being important to picking out errors or fraud; let's not start thinking about how to carve up exceptions to this rule.
I should point out here that my boss (another real actual scientist and all), when I mentioned this whole discussion in a lab meeting, took issue with the idea that this was a job for reviewers. He says the important thing is to have the code available when published, so that other people can replicate it. He's a lot more likely to know than I am what the proper role of a reviewer is, so I'll trust him on that one. But I still think the earlier you provide it, the better.
(Another take entirely: Michael Eisen, one of the co-founders of the Public Library of Science, says the order is all wrong, and we should review after publication, not before. He's written this before, in the wonderfully-titled post "Peer review is f***ed up, let's fix it".)
How do I make sure the code works for reviewers? Good question, and a hard one -- but it's one we have answers for.
First, this is the same damn problem that autotools, CPAN, pip and all the rest have been trying to fix. Yes, there are lots of shortcomings in these tools and these approaches, but these are known problems with at least half-working solutions. This is not new!
Second, this is what VMs and appliances are good at. The Encode project used exactly this approach and provided a VM with all the tools (!) to run the analysis. Yes, it's another layer of complexity (which platform? which player? how to easily encapsulate a working pipeline?); no, you don't get a working 5000-node Hadoop cluster. But it works, and it works on anyone's machine.
What obligation do I have to maintain or improve the code? No more than you can, or want to, provide.
Look: inherent in the question is the assumption that the authors will get hordes of people banging on the doors, asking why your software doesn't compile on Ubuntu Scratchy Coelacanth, or why it crashes when you send it input from /dev/null, or how come the man page is out of date. But for most Free Software projects of any description, that day never comes. They're used by a small handful of people, and a smaller handful than that actually work on it...until they no longer want to, and the software dies, is broken down by soil bacteria, returns to humus and is recycled into water snails. (That's where new Linux distros come from, btw.)
Some do become widely used. And the people who want, and are able, to fix these things do so because they need it to be done. (Or the project gets taken over by The Apache Foundation, which is an excellent fate.) But these are the exception. To worry about becoming one of them is like a teenage band being reluctant to play their first gig because they're worried about losing their privacy when they become celebrities.
In conclusion:
...Fuck it, I hate conclusions (another rant). Just publish the damned code, and the earlier, the better.
Out to the local park around 9.30pm, with coyotes and teenagers to keep me company. I'm not recording the housekeeping/easy/medium/challenge parts, 'cos a lot of it went out the window.
Eta Cassiopeia: unlike previous times I actually noticed a difference in colour (white and gold)...that was nice. I decided to spend some time comparing my eyepieces and doing a semi-half-assed (quarter-assed?) star test. The star test came out the two sides unequal, so I guess I should've taken the time to collimate. And as for comparison, the 25mm anonymous silver Plossl seemed better than the 25mm Celestrom X-Cel. This surprised me.
M13: Fainter than previous times. I'm guessing that's because it's lower now than before (45 deg or so compared to nearly zenith the last tie I looked). Still pretty.
M15: Found it the first time I looked for it! Easy in binos, obvious at 30X, shimmering at 160X. Almost seems to be trailing to the NW, like it was leaving behind a trail. Ver' nice.
M2: Less bright, less obvious, but still straightforward. Maybe a hint of resolution at 320X.
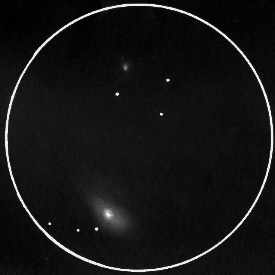
M31: Actually, this is here because I found M32! Woot me! I didn't know which companion it was at the time; I sketched it, then found it matched this one. Could not find M110, but I don't think I was looking far enough.
Eta Persei: Very pretty, very eye-catching. Like Delta Cephei, yellow and blue-green...like the Earth around the Sun.
M34: Stumbled across this while looking through binoculars. Very loose strings of stars, very pretty. Also tried for NGC 956, but no luck...maybe a broken L of stars? Looking at these sketches, I think I probably got the right one, and probably missed a lot.
Uranus: Sought but not found.
NGC 1275 (aka Caldwell 24): Sought but not found. Starhopped, as far as I can tell, to the middle of the Perseus Cluster, but did not see a blessed thing.
Jupiter: Aw, first time through the scope in a long time. Low in the sky, messy as hell, but heart-warming to see.
Moon: Gorgeous, doubly so since I so rarely view it at 3/4 phase. Saw Lunar X, but also another one maybe 1/3 from rim. Sort of.
Pleiades and Hyades: Man, I almost forgot these were up. Awesome.
Tags: astronomy
At $WORK, a user discovered a fun feature of OpenSuSE: that you can segfault Python quite easily. Watch:
$ python
>>> import matplotlib.pyplot
Segmentation fault
$ python
>>> import Bio.PDB
Segmentation fault
The reason, at least for us, is that we'd installed the python-matplotlib package from the OpenSuSE Education repository, and python-numpy from the standard OpenSuSE library. The problem was fixed by running:
sudo zypper install python-numpy-1.6.2-39.1.x86_6
which forced the upgrade from 1.3 to 1.6.
But, whee! you can actually install 1.6.2-39.1 from TWO repos: Education and Science. Yes, my fault; my OpenSuSE installs are all over the fucking map. But I wonder what it might take to ensure that minimum versions are somehow noted in RPMs, or, you know, not having multiple universes of packages. Fuck, I hate OpenSuSE.
For future reference:
Tags: python
I've been reading up on the Apollo missions lately. It followed after reading about Sputnik, then the Mercury missions ("The Right Stuff" is incredible; I now know why Tom Wolfe and Hunter S. Thomson get mentioned in the same breath). Skipped over Gemini -- not much selection at my local library, but I want to fix this oversight -- then lots of Andrew Chaikin, Life magazine and, just finishing right now, First on the Moon (also written with/by Life magazine journalists). I was at the return flight, and kind of skimming over things, when I heard that Neil Armstrong had died.
Clara was going out that night, and I'd been promising the kids for a long time that we'd go out and look at the stars with the telescope, so I figured this was a good time to follow through.
"Hey guys, want to stay up late tonight and look through the telescope?"
"Can we watch movies?"
"Yeah."
"Okay, then."
Note: I do feel bad about not doing this earlier. In my own defense, I have taken them out to a star party this month; I sat out with them at my parents' place this summer (skies dark like you would not BELIEVE) and shown them the Milky Way, told them that we live in a galaxy with billions, BILLIONS of stars. These things are important to me. But I want to do things that are fun for them, not just/only things that are important to me. I try hard to find the balance between making sure they feel welcome, and pestering them about things that bore them to death.
Anyway.
We stayed up and watched Power Rangers S.P.D (two episodes), a little bit of Ghostbusters, and some Pink Panther. And then we put on warm clothes and went out.
It was cloudy, a little bit, but not too much. It was around 8.30pm, and really dark was just in sight. The moon was up -- 67% full, according to my nerdy daily emails -- and low, too low to be seen from our 3rd floor window.
We looked at Saturn first. The highest magnification I had was 48X, so the rings were there, but not amazing -- but the kids saw them. The younger (4 years old) wanted to move the telescope around; the older (6 years old) tried hard not to bump the scope. They both saw through the telescope, which is a big improvement over previous years. (I'm not complaining, though I would've at the time; they weren't ready for that, and I didn't realize that.) It was neat, but probaby not a wonder for them.
We looked at Mars, and that was just a red dot. But I told them that this was where Curiosity was, and I hope that made it interesting.
I pointed it at the moon. The 30x eyepiece framed it nicely, gave them lots of time to look before it drifted out of site. They saw craters, maria, the terminator.
I told them about Neil Armstrong: how he was the first to walk on the moon; how he'd died today; how his family had asked that we wink at the moon. "Why should we?" asked my younger; I think he was confused about the whole thing. "Because his family thought it was something he'd like." "I can only wink two eyes." "That's okay."
"Have you ever seen someone die?" asked my older. "No," I said.
I had a map of the moon. One at a time, I showed them Mare Crisium; hopped from there to Mare Fecundidatis and Mare Nectaris, like two claws on a lobster; and Mare Tranquilitatis, joining the two like the base of the claw. "See up there, right where it goes up to the right? That's where they landed. No, there's not much to see, but that's where it happened." And then we looked up at the moon, counted to three, and winked (or blinked). Goodnight, Mister Armstrong.
Whee, middle of the week observing! Since I got clouded out last week, I didn't want to take any chances.
Followed the structure I set up for myself last time, and here's what I got done.
Any sign of the Milky Way at all? Nope.
Beta Lyrae in eclipse? Nope.
Limiting magnitude: I'd printed out a map of NGC 6823, and following these instructions crossed out the stars I could see. Turns out that, at 100X, I could see 11.79 mag (call it 12th) with effort, and at 160X I could see down to 13.72 mag with effort. Holy shit, that's better than I thought.
The star is approximately 1000 times larger than our Sun's solar radius, and were it placed in the Sun's position, its radius would reach between the orbit of Jupiter and Saturn.
...which, holy crap. Also, it's a carbon star.
Delta Cephei, the original Delta Cephei variable. It's a very, very pretty double; in The Secret Deep, Stephen James O'Meara says it looks like the Earth orbiting the sun. And it does. Double stars aren't my thing, but I'll be coming back to this one.
M16 -- no hint of nebulosity; none.
M29 -- not much to see here...
Berkeley 61 -- no, there's not much there, which should tell you something. Sketched, but more "looks like there should be something here." Since I was in the neigbourhood of M29 and all.
NGC 7235 -- not intentional, but right next to Delta Cephei. I hereby name this the Running Man stick Figure Cluster.
Did not get to NGC 6946 (aka Caldwell 12); clouds started roolling in and I was tired.
And in other news, saw a meteor going across the sky to the NE about 10.33pm. It had broken up into several pieces. Neat!
Tags: astronomy
This is fascinating and wonderful listening: The Kleptones have put together a mixed tape of music similar to what Paul Simon was listening to while putting together Graceland. The Kleptones are awesome on their own, but this is incredible stuff.
Someone on Craigslist was advertising a free 8" pyrex mirror and polishing lap. Here's hoping I get it; it'd be fun to grind my own mirror.
A new Debian wiki page: "Why the name?" explains the origin of package/software names. Surprisingly interesting. Which makes me a nerd.
Tags: music
Excellent overview of one workflow on Stack Overflow.
Mandriva shows how to set up rpm macros to use git during rpmbuild.
Software project A is kept in git. A depends on unrelated project B, so B is configured as a submodule in A. Unfortunately, A's Makefile assumes B's location in that subdirectory, with no provision for looking for its libraries and header files in the usual locations. Good or whack? @FunnelFiasco: "I concur. It's total bullshit."
Unrelated: xpdf crashes on Ubuntu 12.04. Wow.
Tags: git packagemanagement rant
This weekend I took the kids out to Aldergrove Regional Park to the Perseid meteor shower party, organized by Vancouver Parks and the local chapter of the RASC. I went last year with my older son, and the younger was quite eager to go this time around. (Clara was happy we were all going this time, too; last year, the younger stayed up 'til 10pm waiting for his brother, and woke up at 5am upset he wasn't back yet.)
We packed up the tent, flashlights, sleeping bags, PB&J, water bottles, stuffies, binoculars, pillows, lounge chairs, blankets, star atlases, and drove out. We got there at 8.30pm or so and it was already packed. The kids help me set up the tent, and then we were off to the activities.
First we got glow sticks:
And then we went off to get faces painted. That didn't last long, though; we'd already had a very long day with my inlaws and relations by that point, and the kids were bagged. We ducked out of the line after a few minutes, got hot chocolate, then went back to the tent to look at the sky for a while.
Sr. headed off to bed, announcing he "might put his head down for a while". Jr. went with him, but came out in time to watch the ISS fly over. Sr. poked his head out as well, then went back to sleep. Jr. stayed up a little longer, then went to bed about 10.45pm, and I was left with 800 or so of my closest friends.
It was really neat watching the shower with so many people around. There was a park-wide game of Marco Polo, which was funny. And as for the meteors, even before midnight there were a few really bright trails, and everyone would ooh, ahh, and even applaud.
I fell asleep in my lounge chair around 11.30pm, then woke up again about an hour later. There were some really cool trails, but I wouldn't say there was a huge number...I saw one maybe every 2-4 minutes. I finally called it a night at 2am and crawled into the tent.
We got up about 6.30am, ate our PB&J, and started packing up.

We picked up some godawful sweet snacks at a gas station (we did it last year, had to do it this year, next year I'm putting my foot down) and drove home. The kids fell asleep in the back, and then again for two hours in the afternoon...and that never happens.
All in all, a fun time. Recommended if you're in the Vancouver area.
{kind=link}